
This is the fourth post on Machine Learning Questions and Answers series. Look here for previous posts.
In this post, we will see some questions related to Naive Bayes Algorithm.
- What is Naive Bayes Algorithm?
Answer –
One liner for Naive Bayes Algorithm:
Assuming all the feature are independent and are equally important and predicting the things based on prior knowledge and these independence assumptions.
In other words:
- The Naive Bayes Algorithm is a Machine Learning Algorithm for Classification problems
- It is primarily used for text classification
- A few examples are Sentimental analysis, spam filtration, classifying news articles etc
- In short, it is a probabilistic classifier
For example:
- You went to a restaurant for dinner
- You were told to give a feedback
- You are quite happy with the experience and gives feedback as “Happy with the food”
- As per Naive Bayes, all the words given in the feedback are independent of each other and equally important
- So a Naive Bayes Algorithm can be applied here which will then be matched with some historical data of those words
- And at the end of the calculation, we can predict whether the feedback given is positive or negative
- You can get more details in the same post below
2) How could sentimental analysis be used using Naive Bayes Algorithm?
Answer –
- For example, our job is to take a comment and classify whether it is a positive or negative comment
- So we have “comment” as problem instance and Positive or negative as labels
- As I have explained in my previous posts, to solve above classification problem, we will require a training data which has a large body of texts which are labeled as positive or negative
- For example word, “Good” would be labeled as Positive and word “Bad” would be labeled as Negative
Next step would be to fit our data to a standard Machine Learning Algorithm, we will use Naive Bayes Algorithm here.
- In the training phase, the algorithm tries to collect the information to classify any new text as positive or negative
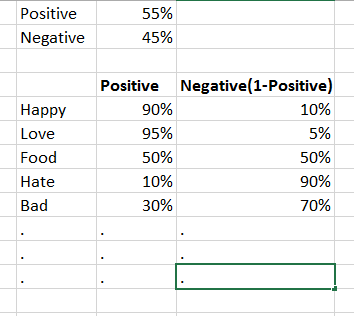
- Let us assume that we have completed the training phase and it resulted in 55% positive words and 45% negative words
- So when a new comment comes, we can divide that comment into different words and we can compute a positive score and a negative score for every word
Let us see how a comment can be recognized whether it is a positive comment or a negative comment.
We have below result from our training phase:

Now a new comment comes and we need to identify whether it is positive or negative.
The comment is “Happy with the Food”
- Naive Bayes Algorithm will calculate a positivity score and Negativity score
- It does this using the pieces of information we got from training phase
Let us first calculate the Positivity score for above comment:
- We will divide the comment into mainly 2 major words, “Happy” and “Food”
- We can ignore some specific words like “with” “the” etc
- Positive score can be computed by multiplying Positive score of “Happy” with positive score of “Food” along with the overall probability that the comment is positive
For example:
Below image would explain how to calculate the positive score for the comment “Happy with the Food”:

As you can see after the multiplication, positive score came as 0.24
Similarly, we can calculate the negative score for the same comment.
Basically Negative score for a word from the training model can be calculated by doing minus from the positive score as explained below:
So if we try to calculate negative score as we did above then:
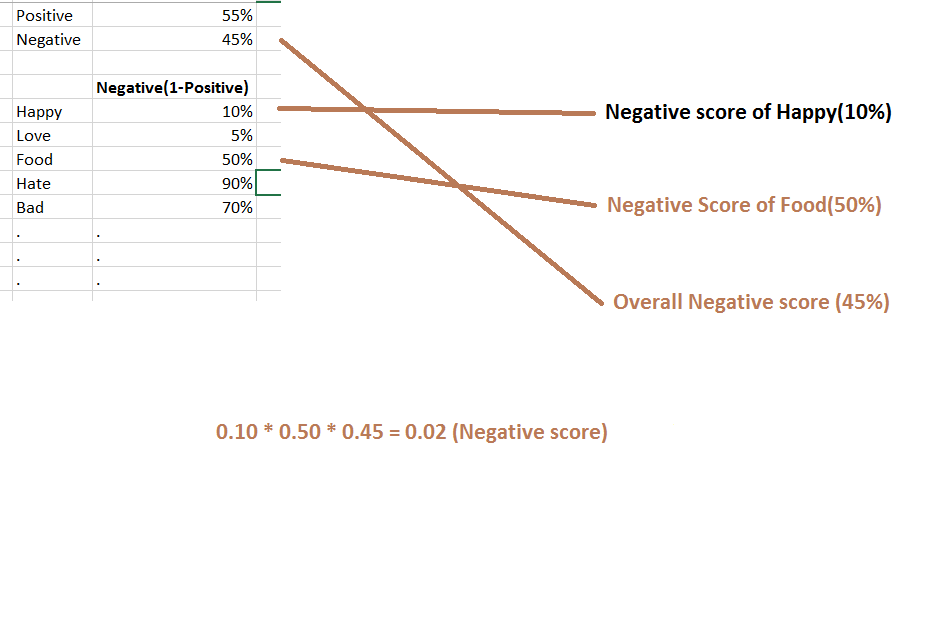
As you can see we got Negative score as 0.02
Here we have taken the example of only 2 words, but it can be computed with n number of words.
Final score is, the comment “Happy with the Food” is positive because positive score 0.24 is greater than Negative score 0.02

This is how Naive Bayes works with Sentimental Analysis.
3) Why Naive Bayes is called naive?
Answer –
The Naive Bayes is called Naive because:
- It makes the assumptions that occurrence of certain features is independent of the occurrence of other features
For example:
- Your job is to identify the fruit based on its color, shape and taste
- Then Orange colored, spherical and tangy fruit is most likely be an Orange fruit
- Even if these features depend on each other, or in the presence of the other features, all these properties individually contribute to the probability that this fruit is Orange
- For example, if there is a fruit which is orange in shape but it is not spherical in shape and it does not taste tangy but still it could be an Orange fruit
Hope it helps.

Best Ever Detail So Far I have learned
LikeLike
Thanks a lot 🙂
LikeLike
Hi Neel,
I really like the way you explained Naive bias in simple words. Very helpful.
Thanks
LikeLike
It’s really helpful material. Thank you
LikeLike