
I have recently started posting related to Machine Learning and I got some very positive feedback from people because they are liking the way I explain Machine Learning related topics in simple words.
As per the demand, I am starting the series of Machine Learning Questions and Answers.
I will keep on posting the questions along with the answers here as soon as I get to know it.
So let us start:
1) What are the types of Machine Learning and what is the difference between Supervised Machine Learning and UnSupervised Machine learning?
Answer – For this, I have already written a post which you can find here.
2) What is the difference between Classification and Clustering?
Answer –
One liner for Classification:
Classifying data into pre-defined categories
One liner for Clustering:
Grouping data into a set of categories
Key difference:
Classification is taking data and putting it into pre-defined categories and in Clustering the set of categories, that you want to group the data into, is not known beforehand.
Let us go a bit deeper into Classification first:
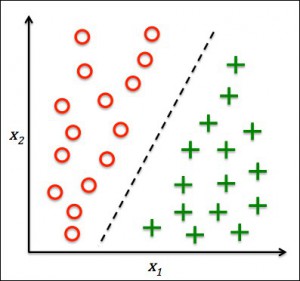
- In classification, you would start with one instance(one object) to be classified
- You would classify it into pre-defined categories which are nothing but the labels
- Do this based on the training data which has already been classified
- For Example – In sentiment analysis, you would classify one comment as positive or negative and you would do this based on the set of training data which are already been classified into positive and negative comments
- So if you understood Supervised Machine Learning then you would realize that Classification is nothing but the Supervised Machine Learning
Simple understanding with an example:
You give your algorithm(your friend) some data(Set of People), called as Training data, and made him learn which data corresponds to which label(Male or Female). Then you point your algorithm to certain data, called as Test data, and ask it to determine whether it is Male or Female. The better your teaching is, the better it’s prediction.
Some real-life examples:
- If the e-mail is a spam or not
- Is the comment on a Facebook post or a Tweet on Twitter is positive or negative
- If the trading day is an Up-day or a down-day
- Handwritten Digit Recognition
- Speech Recognition
- Image Recognition
Example of Classification Algorithm:
- K – Nearest neighbor
- Decision Trees
- Bayesian Classifier
Steps of Classification Setup:

- The problem has to be defined first
- Then you would represent your data in the form of Numerical attributes called Features. This is done both for the training data which has already been classified and the test data which has to be classified in the future
- You would take your training data and feed it into a classification algorithm to train a model
- Take new instance that needs to be classified or take the test data and pass it to classifier to classify
Now let us see something more about Clustering:

- Instead of taking single Instance(As the case of Classification above), we are taking large number of instances
- We divide these number of instances into the groups
- So as we had pre-defined categories in Classification, in clustering the groups are unknown beforehand
- Basically, we do not know before the clusters are formed, what to call those clusters because we would not know until then, what would be the common categories inside these clusters
- Yes, it is UnSupervised Machine Learning
Simple understanding with an example:
In Clustering, you provide the data(Set of people) to the algorithm(your friend) and ask it to group the data.
Now, it’s up to algorithm to decide what’s the best way to the group is? (Gender, Color or age group).
Again, you can definitely influence the decision made by the algorithm by providing extra inputs.
Some Real-life examples:
- How we can divide set of articles such that those articles have the same theme(we do not know the theme of the articles ahead of time)
- Identifying groups of houses according to their house type, value and geographical location
- Earthquake epicenters to identify dangerous zones
- Putting telephone towers in a new city using clustering such that all its user receives optimum single strength
Example of Clustering Algorithm:
- K- Means Algorithm
- Expectation maximization
Steps of Clustering Setup:

- You would start with the problem statement, which is the database which needs to be clustered
- Then you would represent points in that dataset using features.
- No training step here
- You would directly feed the data into Clustering algorithm to find the final clusters, without any training steps
3) Can Classifier and Clustering go hand an hand OR Can Classifier and Clustering work together?
Answer – Yes they can.
For example, you have set of articles -> you divide these articles into the clusters based on the tags -> The Articles are grouped based on the tags
Now you have an article -> Article is sent to Classifier and Classifier will assign one of the tags from the tags that are discovered during Clustering above – > Tag is identified
So basically, the articles which are grouped based on the tags into different clusters are becoming the training data for the Classifier.
Conclusion:
- Classification assigns the category to 1 new item, based on already labeled items while Clustering takes a bunch of unlabeled items and divide them into the categories
- In Classification, the categories\groups to be divided are known beforehand while in Clustering, the categories\groups to be divided are unknown beforehand
- In Classification, there are 2 phases – Training phase and then the test phase while in Clustering, there is only 1 phase – dividing of training data in clusters
- Classification is Supervised Learning while Clustering is UnSupervised Learning.
Hope it helps.

I have noticed you don’t monetize neelbhatt.com, don’t waste your traffic, you can earn extra
bucks every month with new monetization method.
This is the best adsense alternative for any type of website
(they approve all websites), for more info simply search in gooogle:
murgrabia’s tools
LikeLike
I’d like to do a PAM clustering with about 1000 observations, capture the mediod obs and as I add a few new ones at a time, calculate their cluster by distance to the mediods. So far, so good. Easy to do. When I’ve accumulated enough new ones, I want to re-cluster but define a group of my observations to fixed clusters so their cluster # doesn’t change, and let the rest fall where they may. How can I do that,, if at all?
LikeLike