
I have started the series of Machine Learning Questions and Answers, you can find the first post here.
Let us see some more questions and answers.
- What is OverFitting in Machine Learning? OR Is OverFitting good or bad in Machine Learning?
Answer –
Overfitting is not good for Machine learning projects.
As the name suggests, it is nothing but trying to fit something over than required.
One liner for Overfitting:
When you remembered but have not learned something, thus you are not prepared for the future
Definition:
- So Overfitting occurs When we capture low-level details in a particular data set but we fail to capture the higher level, more abstract details of that data set. Thus it creates the problem for the future examples
- In other words, Overfitting happens when a model learns the detail and noise in the training data to the extent that it negatively impacts the performance of the model on new data
- And as per Wikipedia – Overfitting is the production of an analysis that corresponds too closely or exactly to a particular set of data, and may, therefore, fail to fit additional data or predict future observations reliably.
Real life example of Overfitting:
- You started reading a chemistry book
- You read every single low-level detail like every single letter and digit
- You read the whole book from start to end
- But what if you can not think about the bigger picture like relating different topics with each other, how one topic is related to another topic etc
- Thus you have remembered the book but have not learned it
- So if someone comes and asks you something from that book, it is not sure whether you can answer all of them
Let us see some examples:
You have some data and you put it into the X and Y axis as below:

If you try to separate the X and 0 something like below:

Though it looks valid, it looks so bad and may create a problem in future. This may happen when you take data too literally. So in above example, this may work perfectly for current data but what if some new data is added, it will not work perfectly.
When you can just take something simple as below:

By this, if you add some more data then also the distance of 0 would be lesser compared to the line which we drew above.
In short, prepare for future instead of giving too much time to the present.
Let us take some visual examples:
For example, you want to create a program which can identify the lion.
In this case, we are overfitting when we collect very basic and complex data like height and width of the lion some other very minor and deep details as below:
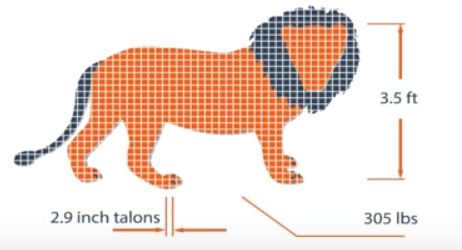
So the program will perfectly identify a lion which comes with little bit similar details as mentioned above, but this would become useless incase of identifying some new examples like a White Lion.

The program would fail to identify White Lion because it was trained with some unnecessary deep details instead of some abstract and useful details.
2) How can we avoid Overfitting?
Answer –
We can avoid Overfitting by splitting the data 3 way:

- Training set
- Cross-Validation
- Test set
This way we are assuring that the model is not dependant on any particular set
Apart from this, you can:
- Keep it Simple
- Feature selection: consider using fewer feature combinations and decrease the number of numeric attributes bins
- Increase the amount of regularization used
- Increase the amount of training data examples
- Increase the number of passes on the existing training data
Hope it helps
